A Closer Look at Azure AI Search's Scalar Quantization and 'Stored' Property Enhancements

Azure AI Search has recently launched new storage limits, enhancing its capabilities with two innovative features aimed at optimizing price-performance: Scalar Quantization and a new "stored" property for vector fields. This blog post delves into these powerful features and provides a detailed walkthrough of their implementation using Python Jupyter notebooks.
What are these features?
Scalar Quantization
Scalar Quantization is a compression technique for vector data. This method transforms high-dimensional vectors into a lower-bit representation, resulting in substantial storage savings. By reducing storage costs, Scalar Quantization enhances search performance without significantly compromising result accuracy.
Stored Property
The new "stored" property introduces flexibility in managing storage costs. When set to False, the property isn't stored, which reduces the overall index size and cost while maintaining searchability.
Implementation
The implementation process involves several steps:
Installation: Install all necessary libraries to ensure the workspace has the latest versions of Azure Search Documents, OpenAI, and other dependencies.
Index Creation: Create or update indexes using the Azure Search Documents Index Client. The scenarios specified include:
baseline: The original index without optimizations.stored: The Stored Property is set to False.scalar-quantization: Applies Scalar Quantization compression.both: Combines Scalar Quantization and Stored Property optimizations.
Document Transformation and Uploading: Transform the dataset into a list of dictionaries suitable for Azure AI Search ingestion. Upload these transformed documents in batches to the respective indexes created in the previous step.
Installation of Required Libraries
Before we dive into the implementation, we need to install and upgrade the necessary Python libraries for the project:
azure-search-documents: This is the Azure Search Documents library, which provides the necessary tools to interact with the Azure Search service. I'll be using the latest preview version (11.6.0b3) as these features are in beta.openai: This library is used to interact with the OpenAI API, which provides various AI embedding models. I'll be using the "text-embedding-ada-002" model at 1536 dimensions.python-dotenv: This library is used to read key-value pairs from a .env file and set them as environment variables.azure-identity: This library provides Azure Active Directory (Microsoft Entra) token authentication support across the Azure SDK.datasets: This library provides a collection of datasets with easy-to-use APIs for downloading and using them for model training and evaluation.matplotlib: This is a plotting library for Python and its numerical mathematics extension, NumPy. It provides an object-oriented API for embedding plots into applications.prettytable: This library is used to easily display tabular data in a visually appealing ASCII table format.The
%pip installcommand is a magic command in Jupyter notebooks, used to run pip commands directly from the notebook.
Initialize Necessary Imports
The code block below imports the necessary libraries and modules for the implementation.
I'm first going to authenticate using API Keys, I really should be using managed identity though as it's much more secure.
# Load environment variables from .env file
load_dotenv()
# Set up OpenAI client based on environment variables
AZURE_OPENAI_ENDPOINT: str = os.getenv("AZURE_OPENAI_ENDPOINT")
AZURE_OPENAI_API_KEY: str = os.getenv("AZURE_OPENAI_API_KEY")
AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME: str = os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME")
AZURE_OPENAI_API_VERSION: str = "2023-05-15"
# Set up Search Service client based on environment variables
SEARCH_SERVICE_ENDPOINT = os.getenv("AZURE_SEARCH_SERVICE_ENDPOINT")
SEARCH_SERVICE_API_KEY = os.getenv("AZURE_SEARCH_ADMIN_KEY")
# Other constants
INDEX_NAME = "dbpedia-1m"
# Authentication method flag
use_aad_for_search = False # Set based on your authentication method
# Choose the correct credential based on your authentication method
credential = (
DefaultAzureCredential()
if use_aad_for_search
else AzureKeyCredential(SEARCH_SERVICE_API_KEY)
)
# Initialize the SearchIndexClient for creating indexes
index_client = SearchIndexClient(
endpoint=SEARCH_SERVICE_ENDPOINT, credential=credential
)
# Initialize the SearchClient
search_client = SearchClient(endpoint=SEARCH_SERVICE_ENDPOINT, credential=credential, index_name=INDEX_NAME)
Dataset Processing and Conversion
For this experiment, I'm leveraging the below dataset with pre-computed embeddings because it's pretty lightweight and clean and has 1M which is a decent number of vectors to represent a production scenario.
KShivendu/dbpedia-entities-openai-1M · Datasets at Hugging Face
This Python code block loads a dataset, and processes it by generating unique IDs and extracting relevant fields. It uses multiprocessing and caching for efficient data processing.
import uuid
from datasets import load_dataset
# Constants
DATASET_NAME = "KShivendu/dbpedia-entities-openai-1M"
BATCH_SIZE = 2000
NUM_PROC = 32
def process_batch(batch_data):
"""Processes a batch of data by generating unique IDs and extracting relevant fields."""
return {
"id": [str(uuid.uuid4()) for _ in range(len(batch_data["title"]))], # Generate unique IDs using uuid4
"title": batch_data["title"],
"text": batch_data["text"],
"embedding": batch_data["openai"], # Ensure this field name matches your dataset schema
}
# Load the entire dataset
dataset = load_dataset(DATASET_NAME, split="train")
# Enable caching to avoid reprocessing if the script is run multiple times
documents_to_index = dataset.map(
process_batch,
batched=True,
batch_size=BATCH_SIZE, # Adjust batch size based on your system's memory capacity and dataset size
num_proc=NUM_PROC, # Adjust based on the number of available CPU cores
load_from_cache_file=True,
remove_columns=dataset.column_names,
)
Index Creation
Next, let's create indexes in Azure AI Search with different scenarios I want to benchmark against.
DIMENSIONS = 1536
HNSW_PARAMETERS = {"m": 4, "metric": "cosine", "ef_construction": 400, "ef_search": 500}
DEFAULT_OVERSAMPLING = 10
QUANTIZED_DATA_TYPE = "int8"
def create_fields(scenario):
return [
SimpleField(name="id", type=SearchFieldDataType.String, key=True),
SearchField(name="title", type=SearchFieldDataType.String, searchable=True),
SearchField(name="text", type=SearchFieldDataType.String, searchable=True),
SearchField(
name="embedding",
type="Collection(Edm.Single)",
vector_search_dimensions=DIMENSIONS,
vector_search_profile_name=f"profile-{scenario}",
stored=(scenario == "baseline" or scenario == "scalar-quantization"),
),
]
def create_vector_search_profiles(scenario):
return [
VectorSearchProfile(
name=f"profile-{scenario}",
algorithm_configuration_name=f"hnsw-{scenario}",
compression_configuration_name=(
f"compression-{scenario}"
if scenario not in ["baseline", "stored"]
else None
),
vectorizer="myOpenAI",
)
]
def create_algorithms(scenario):
return [
HnswAlgorithmConfiguration(
name=f"hnsw-{scenario}",
kind=VectorSearchAlgorithmKind.HNSW,
parameters=HnswParameters(**HNSW_PARAMETERS),
)
]
def create_compressions(scenario):
compressions = []
if scenario not in ["baseline", "stored"]:
compressions.append(
ScalarQuantizationCompressionConfiguration(
name=f"compression-{scenario}",
rerank_with_original_vectors=True,
default_oversampling=DEFAULT_OVERSAMPLING,
parameters=ScalarQuantizationParameters(quantized_data_type=QUANTIZED_DATA_TYPE),
)
)
return compressions
def create_vectorizers():
return [
AzureOpenAIVectorizer(
name="myOpenAI",
kind="azureOpenAI",
azure_open_ai_parameters=AzureOpenAIParameters(
resource_uri=AZURE_OPENAI_ENDPOINT,
deployment_id=AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME,
api_key=AZURE_OPENAI_API_KEY,
),
),
]
def create_or_update_index(client, index_name, scenario):
fields = create_fields(scenario)
vector_search_profiles = create_vector_search_profiles(scenario)
algorithms = create_algorithms(scenario)
compressions = create_compressions(scenario)
vectorizers = create_vectorizers()
vector_search = VectorSearch(
profiles=vector_search_profiles,
algorithms=algorithms,
compressions=compressions,
vectorizers=vectorizers,
)
index = SearchIndex(
name=f"{index_name}-{scenario}", fields=fields, vector_search=vector_search
)
client.create_or_update_index(index=index)
print(f"Index for {scenario} created or updated successfully.")
scenarios = ["baseline", "stored", "scalar-quantization", "both"]
for scenario in scenarios:
create_or_update_index(index_client, INDEX_NAME, scenario)
Upload Documents to Multiple Indexes with Concurrency
Many people have their preferred way of indexing documents. Personally, I prefer the Push API approach when doing prototypes. I also recommend using logging to see what's going on while indexing large datasets. The indexing time for the below job took ~15 mins per index.
from concurrent.futures import ThreadPoolExecutor
import logging
BATCH_SIZE = 1000
NUM_WORKERS = 10
def create_search_client(index_name):
return SearchClient(
endpoint=SEARCH_SERVICE_ENDPOINT, index_name=index_name, credential=credential
)
def upload_documents_to_index(client, documents):
def upload_batch(batch):
try:
result = client.merge_or_upload_documents(documents=batch)
if result.is_error:
for error in result.errors:
logging.error(
f"Failed to upload document with ID: {error.key}, error: {error.error.message}"
)
else:
logging.info("Successfully uploaded batch")
except Exception as e:
logging.error(f"Failed to upload batch: {e}")
with ThreadPoolExecutor(max_workers=NUM_WORKERS) as executor:
for i in range(0, len(documents), BATCH_SIZE):
batch = documents[i : i + BATCH_SIZE]
executor.submit(upload_batch, batch)
index_names = ["dbpedia-1m-baseline", "dbpedia-1m-stored", "dbpedia-1m-scalar-quantization", "dbpedia-1m-both"]
for index_name in index_names:
client = create_search_client(index_name)
upload_documents_to_index(client, transformed_documents)
Index Statistics Retrieval
Let's now take a look at some statistics of these indexes.
index_names = [
"dbpedia-1m-baseline",
"dbpedia-1m-stored",
"dbpedia-1m-scalar-quantization",
"dbpedia-1m-both",
]
for index_name in index_names:
index_stats = index_client.get_index_statistics(index_name)
print(index_stats)
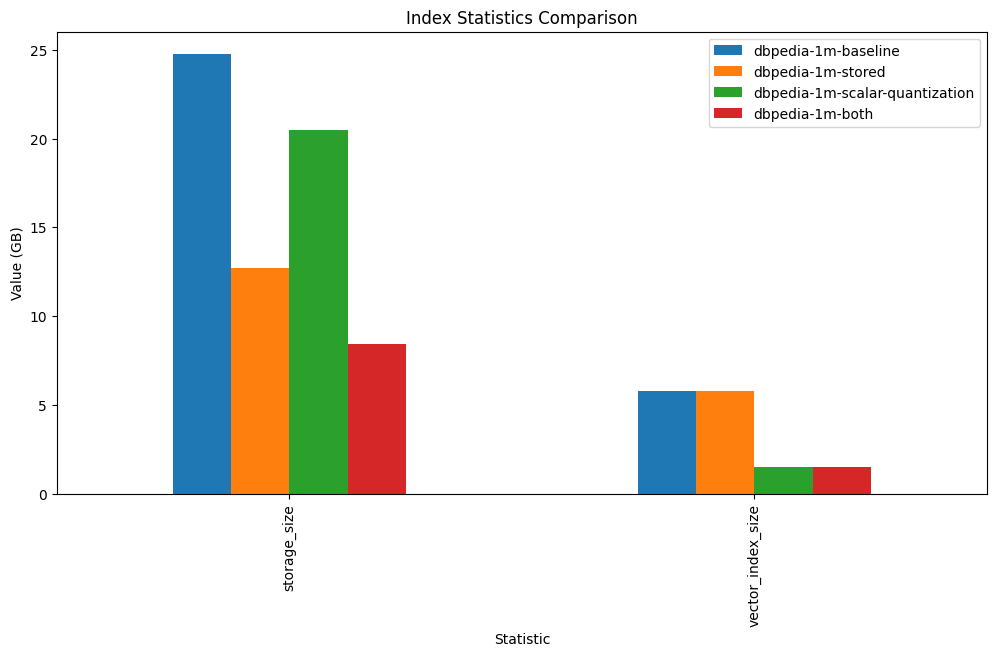
Index Statistics Comparision
The comparison of index statistics helps us understand the benefits of these new features better. We can visually compare the storage size and vector index size for four different index configurations in Azure AI Search using bar charts.
Through a direct comparison, we can see the advantages that each new feature introduces:
dbpedia-1m-baseline represents our control group, an index without any form of optimization.
dbpedia-1m-stored shows how deselecting the storage of vector fields decreases the storage size.
dbpedia-1m-scalar-quantization applies scalar quantization to condense vector data, which drastically reduces the vector index size.
dbpedia-1m-both combines the former two methods, yielding the greatest reduction in storage size.
This bar chart allows us to visually dissect the storage size and vector index size across the four different index configurations. We see the tangible benefits of each optimization feature employed.
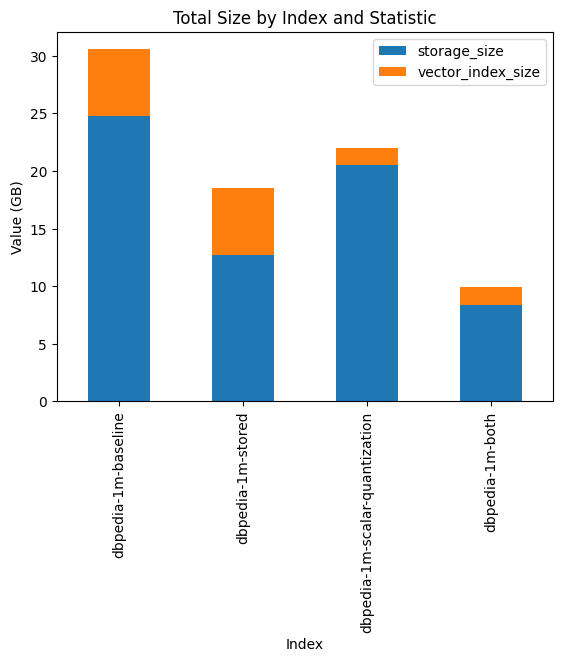
The stacked bar chart paints a clear picture of the total size per index. From this, we glean how each method contributes to the overall size, highlighting the synergistic effect of combining storage optimizations with scalar quantization.
Summary Table
| Index | Storage Savings vs. Baseline | Vector Index Size Savings vs. Baseline |
| dbpedia-1m-stored | 48% | 0% |
| dbpedia-1m-scalar-quantization | 17% | 74% |
| dbpedia-1m-both | 66% | 74% |
Search Relevance and Score Consistency
The search results across different index configurations—dbpedia-1m-baseline, dbpedia-1m-stored, dbpedia-1m-scalar-quantization, and dbpedia-1m-both—showcase that the application of scalar quantization and stored property optimizations does not adversely affect search relevance. The scores across the indexes remain consistent, underscoring that even with significant storage savings, the precision and quality of search results are maintained. Note, that reranking and oversampling are recommended for mitigating the slight recall loss that comes with quantization.
from prettytable import PrettyTable
from azure.search.documents import SearchClient
from azure.search.documents.models import VectorizableTextQuery
from azure.core.credentials import AzureKeyCredential
index_names = [
"dbpedia-1m-baseline",
"dbpedia-1m-stored",
"dbpedia-1m-scalar-quantization",
"dbpedia-1m-both",
]
query = "Who is considered one of the pioneers in computational linguistics?"
for index_name in index_names:
# Create a new SearchClient for each index
search_client = SearchClient(
endpoint=SEARCH_SERVICE_ENDPOINT,
index_name=index_name,
credential=AzureKeyCredential(SEARCH_SERVICE_API_KEY),
)
vector_query = VectorizableTextQuery(
text=query, k_nearest_neighbors=5, fields="embedding"
)
results = search_client.search(
search_text=None,
vector_queries=[vector_query],
top=5,
)
# Create a PrettyTable instance
table = PrettyTable()
table.field_names = ["ID", "Title", "Score"]
for result in results:
table.add_row([result['id'], result['title'], result['@search.score']])
print(f"Results for index: {index_name}")
print(table)
print("\n")
----------------------------------
Results for index: dbpedia-1m-baseline
Title Score
Victor Yngve 0.8812048
Martin Kay 0.87292093
Cliff Shaw 0.86878633
Ronald Langacker 0.86675614
Leonard Talmy 0.8651312
Results for index: dbpedia-1m-stored
Title Score
------------------ -----------
Victor Yngve 0.8812535
Martin Kay 0.8729611
Cliff Shaw 0.8687767
Ronald Langacker 0.8668215
Leonard Talmy 0.8651515
Results for index: dbpedia-1m-scalar-quantization
Title Score
------------------ ------------
Victor Yngve 0.88120604
Martin Kay 0.8729202
Cliff Shaw 0.8687848
Ronald Langacker 0.8667554
Leonard Talmy 0.8651313
Results for index: dbpedia-1m-both
Title Score
------------------ ------------
Victor Yngve 0.88120604
Martin Kay 0.8729202
Cliff Shaw 0.8687848
Ronald Langacker 0.8667554
Leonard Talmy 0.8651313
In conclusion, the new scalar quantization and stored property features introduced in Azure AI Search offer promising optimizations for price-performance. Scalar Quantization enables significant savings in storage costs without noticeably compromising result accuracy, while the stored property allows more flexible management of storage costs. The implementation of these features is straightforward, and their impact on search performance is highly beneficial.
Let me know what else you'd like to deep dive into about Azure AI Search and Vector Embeddings for Generative AI and RAG apps. :)



