
Leveraging OpenAI's New Text-Embedding-3 Large Model in Azure AI Search
How might we explore how variable dimensions affect vector storage size?


Introduction
When integrated with OpenAI's latest text-embedding-3-large model, Azure AI Search offers remarkable embedding generation and storage optimization capabilities. This article demonstrates how to employ Azure OpenAI Service for generating embeddings and storing them efficiently within Azure AI Search.
Objectives of This Exploration
Our journey today revolves around three pivotal areas:
Introducing Azure OpenAI Service: How customers can seamlessly take advantage of OpenAI's cutting-edge new embedding models within your Azure environment.
Using Azure AI Search as a Vector Store: The latest addition to Azure AI Search capabilities, enabling efficient storage and retrieval of high-dimensional vector embeddings.
Discovering OpenAI's new Embedding Model: We dive into the new model's capabilities, focusing on its variable dimensions feature and how it revolutionizes data representation and retrieval processes.
Setting Up Your Environment
Start by installing the necessary libraries to interact with Azure AI Search and Azure OpenAI's services:
!pip install azure-search-documents azure-identity
!pip install openai
!pip install python-dotenv
!pip install langchain tiktoken
Authentication Methods
Ensure your Azure OpenAI credentials are correctly set up. Lots of customers usually ask about the best way to authenticate into Azure AI services. In this example, I'll show you both using Azure Active Directory (AAD) and API Keys.
import os
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
from dotenv import load_dotenv
from openai import AzureOpenAI
# Set up OpenAI client based on environment variables
load_dotenv()
AZURE_OPENAI_ENDPOINT: str = os.getenv("AZURE_OPENAI_ENDPOINT")
AZURE_OPENAI_API_KEY: str = os.getenv("AZURE_OPENAI_API_KEY")
AZURE_OPENAI_API_VERSION: str = "2023-05-15"
AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME: str = os.getenv(
"AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME"
)
credential = DefaultAzureCredential()
token_provider = get_bearer_token_provider(
credential, "https://cognitiveservices.azure.com/.default"
)
# Set this flag to True if you are using Azure Active Directory
use_aad_for_aoai = False
if use_aad_for_aoai:
# Use Azure Active Directory (AAD) authentication
client = AzureOpenAI(
azure_endpoint=AZURE_OPENAI_ENDPOINT,
api_version=AZURE_OPENAI_API_VERSION,
azure_ad_token_provider=token_provider,
)
else:
# Use API key authentication
client = AzureOpenAI(
api_key=AZURE_OPENAI_API_KEY,
api_version=AZURE_OPENAI_API_VERSION,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
)
Generating Embeddings of Various Sizes
I like t-shirt sizing things in groups of 3. Using the text-embedding-3-large model, let's generate embeddings of different t-shirt sizes.
def generate_small_embedding(text: str):
# Generate 256d embeddings for the provided text
embeddings_response = client.embeddings.create(
model=AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME, input=text, dimensions=256
)
return embeddings_response.data[0].embedding
def generate_medium_embedding(text: str):
# Generate 1536d embeddings for the provided text
embeddings_response = client.embeddings.create(
model=AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME, input=text, dimensions=1536
)
return embeddings_response.data[0].embedding
def generate_large_embedding(text: str):
# Generate 3072d embeddings for the provided text
embeddings_response = client.embeddings.create(
model=AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME, input=text, dimensions=3072
)
return embeddings_response.data[0].embedding
text-embedding-3-large model uses a technique called Matroshkya Representation Learning during training to enable variable dimensions. I may dive into this a later date...Read more: [2205.13147] Matryoshka Representation Learning (arxiv.org)Verify the dimension length
Let's check the dimensionality of our embeddings to ensure correctness:
print(len(generate_small_embedding("Hello, world!"))) # Outputs: 256
print(len(generate_medium_embedding("Hello, world!"))) # Outputs: 1536
print(len(generate_large_embedding("Hello, world!"))) # Outputs: 3072
Evaluating Embedding Sizes
It's crucial to understand the storage implications of embeddings:
import sys
def print_vector_size(text: str, generator_function, description: str):
# Generate an embedding for the text using the specified generator function
embedding_vector = generator_function(text)
# Measure the size of the vector embedding in bytes
vector_size_bytes = sys.getsizeof(embedding_vector)
# Print the size
print(f"Size of the {description} vector embedding in bytes: {vector_size_bytes}")
# Example text
text = "Hello, world!"
# Print the size for each type of embedding
print_vector_size(text, generate_small_embedding, "small")
print_vector_size(text, generate_medium_embedding, "medium")
print_vector_size(text, generate_large_embedding, "large")
Let's visualize the output:
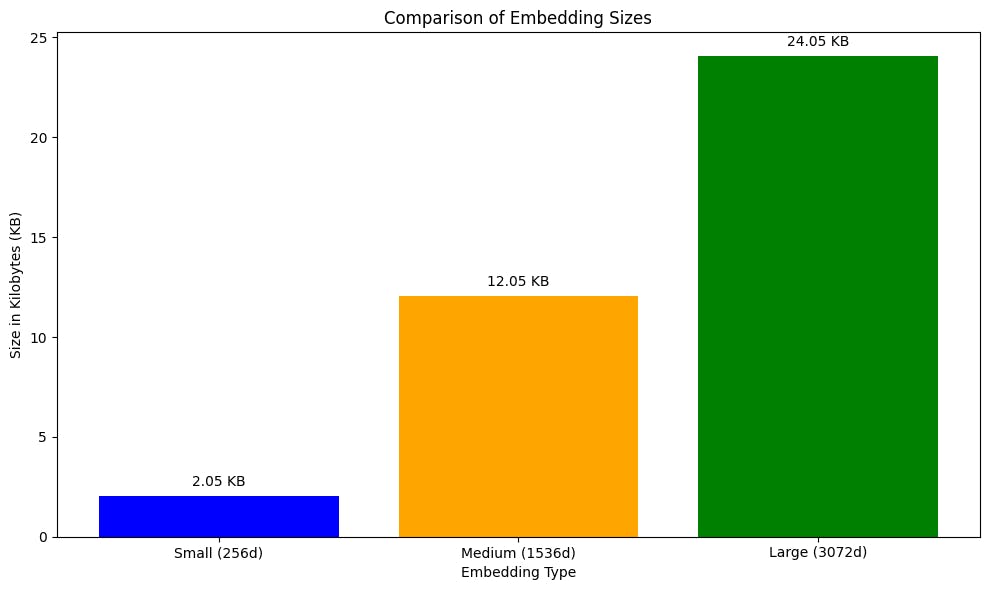
Relative Differences
When comparing the embedding sizes relative to the medium (1536d) embedding:
The small (256d) embedding is significantly smaller than the medium embedding. Specifically, it is approximately
((12344 - 2104) / 12344) * 100 ≈ 82.96%smaller. This highlights the efficiency of using smaller embeddings for applications where memory usage is a critical constraint, though it may come at the cost of losing some detail or expressive power.The large (3072d) embedding is larger than the medium embedding. It is approximately
((24632 - 12344) / 12344) * 100 ≈ 99.41%larger. The increased size of the large embeddings suggests a higher level of detail or expressive power, which can be beneficial for tasks requiring high accuracy.
Configure an Azure AI Search vector index
Let's take a look at how we can leverage these embeddings in a real-world vector store leveraging Azure AI Search, the go-to vector database on Azure.
from azure.search.documents.indexes import SearchIndexClient
from azure.core.credentials import AzureKeyCredential
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents import SearchClient
from azure.search.documents.indexes.models import (
SearchIndex,
SimpleField,
SearchableField,
SearchField,
SearchFieldDataType,
VectorSearch,
HnswAlgorithmConfiguration,
VectorSearchProfile,
VectorSearchAlgorithmKind,
)
from azure.identity import DefaultAzureCredential
import os
# Load environment variables
search_service_endpoint = os.getenv("AZURE_SEARCH_SERVICE_ENDPOINT")
search_service_api_key = os.getenv("AZURE_SEARCH_ADMIN_KEY")
Just like how we authenticated with Azure OpenAI Service, we must do the same for Azure AI Search, here are a couple of ways using Managed Identity or API Keys, pick your choice!
# Authentication method flag
use_aad_for_search = False # Set based on your authentication method
# Choose the correct credential based on your authentication method
credential = (
DefaultAzureCredential()
if use_aad_for_search
else AzureKeyCredential(search_service_api_key)
)
Create indexes with the required dimensions:
# Initialize the SearchIndexClient for creating indexes
index_client = SearchIndexClient(
endpoint=search_service_endpoint, credential=credential
)
# Index names and their corresponding vector dimensions
index_info = {
"small": {"name": "index-256d", "dimension": 256},
"medium": {"name": "index-1536d", "dimension": 1536},
"large": {"name": "index-3072d", "dimension": 3072},
}
def create_or_update_index(index_name, dimensions):
fields = [
SimpleField(name="id", type=SearchFieldDataType.String, key=True),
SearchableField(name="text", type=SearchFieldDataType.String),
SearchField(
name="vector",
type=SearchFieldDataType.Collection(SearchFieldDataType.Single),
vector_search_dimensions=dimensions,
vector_search_profile_name="my-vector-profile",
),
]
vector_search = VectorSearch(
algorithms=[
HnswAlgorithmConfiguration(
name="my-hnsw", kind=VectorSearchAlgorithmKind.HNSW
)
],
profiles=[
VectorSearchProfile(
name="my-vector-profile", algorithm_configuration_name="my-hnsw"
)
],
)
index = SearchIndex(name=index_name, fields=fields, vector_search=vector_search)
result = index_client.create_or_update_index(index=index)
# Create or update each index and initialize SearchClient instances
search_clients = {}
for size, info in index_info.items():
create_or_update_index(info["name"], info["dimension"])
search_clients[size] = SearchClient(
endpoint=search_service_endpoint, index_name=info["name"], credential=credential
)
Now that we have successfully created the following three indexes:
| Index Name | "Vector" Field Dimensions |
| index-256d | 256 |
| index-1536d | 1536 |
| index-3072d | 3072 |
Managing and Loading Data
Load and chunk the dataset for optimal embedding generation:
with open('./data/state_of_the_union.txt', 'r', encoding='utf-8') as file:
text_content = file.read()
from langchain.text_splitter import CharacterTextSplitter
# Initialize the text splitter with a specific chunk size
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=100, chunk_overlap=0
)
texts = text_splitter.split_text(text_content)
Generate Embeddings for each chunk
Now that I have chunks, I want to generate embeddings and organize them into data frames.
import pandas as pd
def create_embedding_df(texts, embedding_function):
data = []
for i, text in enumerate(texts):
# Generate embedding
vector = embedding_function(text)
# Append the data with an ID, the original text, and the generated vector
data.append({"id": str(i), "text": text, "vector": vector})
# Create a DataFrame
df = pd.DataFrame(data, columns=["id", "text", "vector"])
return df
# Process the texts with each embedding function and create the DataFrames
df_small = create_embedding_df(texts, generate_small_embedding)
df_medium = create_embedding_df(texts, generate_medium_embedding)
df_large = create_embedding_df(texts, generate_large_embedding)
# Convert DataFrames to lists of dictionaries to get into an upsertable format for AI Search
documents_small = df_small.to_dict('records')
documents_medium = df_medium.to_dict('records')
documents_large = df_large.to_dict('records')
Uploading to Azure AI Search
Upload the document embeddings to your Azure AI Search index and verify success:
# Define a dictionary mapping index sizes to their corresponding documents
documents_dict = {
"small": documents_small,
"medium": documents_medium,
"large": documents_large,
}
# Loop through each index size and upload the documents
for size, documents in documents_dict.items():
upload_result = search_clients[size].upload_documents(documents=documents)
Understanding Index Statistics
Retrieve and display index statistics to analyze storage and vector index sizes:
def fetch_index_statistics(index_info):
# Prepare a list to hold the index statistics
stats_data = []
# Iterate over each index in index_info
for key, value in index_info.items():
index_name = value["name"]
# Fetch the statistics for the current index
stats = index_client.get_index_statistics(index_name=index_name)
# Append the statistics to our list
stats_data.append(
{
"Index Name": index_name,
"Storage Size (bytes)": stats["storage_size"],
"Vector Index Size (bytes)": stats["vector_index_size"],
"Document Count": stats["document_count"],
}
)
# Convert the list of statistics into a DataFrame for nicer display
return pd.DataFrame(stats_data)
# Fetch the statistics for each index and store in a DataFrame
df_stats = fetch_index_statistics(index_info)
# Display the DataFrame
print(df_stats)
Visualize the storage and vector index sizes to assess the impact of embedding dimensionality:
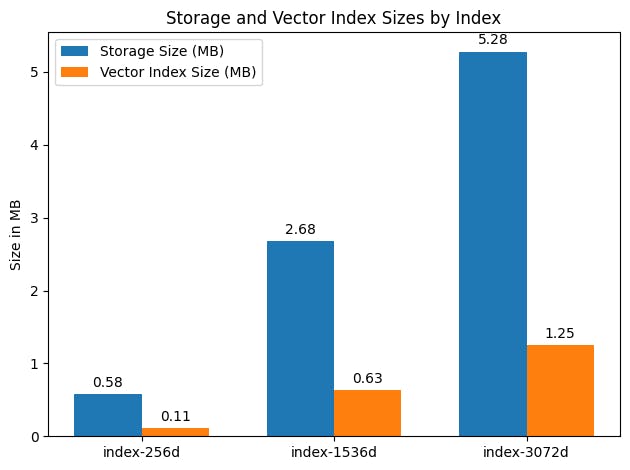
Concluding Insights
Storage Size (MB) and Vector Index Size (MB) are approximations, calculated from bytes to MB (1 MB = 1,048,576 bytes). View Vector index size documentation to learn more.
The Document Count indicates the total number of chunks/documents stored in each index.
These statistics highlight the relationship between the dimensionality of the embeddings and the storage requirements. As the dimensionality increases, so does the storage and vector index size, reflecting the trade-off between detail (or accuracy) and resource utilization.
Relative differences
The index-1536d is approximately 4.6x larger in storage size and 5.7x larger in vector index size than the index-256d.
The index-3072d is approximately 2x larger in storage size and 2x larger in vector index size than the index-1536d, showcasing the significant impact of increasing the embedding dimensionality on storage and indexing resource requirements.
These comparative insights demonstrate how embedding dimensionality influences not just the accuracy and detail of stored embeddings but also the practical aspects of storage and indexing within Azure AI Search, emphasizing the need to balance between embedding detail and resource efficiency.
Join me in my next blog where we will evaluate retrieval quality metrics of this cutting-edge new embedding model!